
# 一、redis 数据类型篇
rdis 常见的数据类型及应用场景
# String
String 是最基本的 key-value 结构,key 是唯一标识 value 是具体的值 value 不仅是字符串,还可以是数字 (整数或者浮点数) value 最多可以容纳的数据长度是 512M,
# 内部实现:
String 底层实现的数据结构是 int 和 SDS (简单动态字符串)
- SDS 不仅可以保存文本数据还可以保存二进制数据,SDS 使用了 len 属性来判断字符串是否结束,
- SDS 获取字符串长度的时间复杂度是 O1
- Redis 的 SDS api 是安全的,拼接字符前会判断空间是否满足要求,不满足会自动扩容,所以不好导致缓冲区溢出
# 常用场景:
- 常规计数:计算点赞、转发、库存数量、阅读量
- 分布式: 使用命令不存在此键就插入成功,而解锁 就是删除键,解锁的额操作需要判断,使用需要保证原子性操作,可以使用 Lua 脚本
- 共享 Session 使用 Session 来保存用户的会话状态。
- 热点数据缓存
# List
list 是简单的字符串列表,按照插入顺序排序,可以从头部或尾部向 List 添加元素,列最大长度为 2^32-1
# 内部实现
在 3.2 版本之前内部是采用双向链表或者压缩列表实现的,在后面就只用 quicklist 实现,替代了双向链表和压缩列表
# 常用场景
- 消息队列 :如果要实现消息队列,需要实现消息的保序、可靠、处理重复的消息
保序的话,List 本身就是先进先出,已经是有序的了,并且 redis 提供了 BRPOP 命令,称为阻塞式读取,客户端在没有读到 redis 数据时自动阻塞,直到有数据了在读取。 处理重复消息,需要自己生成一个全局 ID,需要记录已经处理过的消息 ID. 而在消息可靠性方面,redis 在用户读取消息后就不会保存,若消费者消费失败消息就丢失了, 对于这个问题,可以再开一个消息队列,作为备份暂存,消费成功后再去删除掉备份的即可。
存在的问题
- 无法支持消费者组
- 无法支持多个消费者消费同一个消息
# Hash
Hash 是一个键值对集合,其中 value=[{field1,value1},{fieldN,valueN}]
# 内部实现
hash 类型的底层数据结构采用的是压缩列表或哈希表 。如果 hash 类型的元素格式小于 512 个 并且值小于 64 字节, 就使用压缩列表,反之则使用 hash 表 而在 redis7.0 中,压缩列表数据结构被废弃了,就采用 listpack 来实现
# 使用场景
通常用来缓存一些对象的属性,例如用户信息、购物车(用户 Id,商品 id,数量)
# Set
set 类型是无序唯一的键值集合,他的存储顺序不会按照插入的先后来存储,一个集合最多可存储 2^32-1 个元素,可以进行并交差集运算,也可以支持多个集合去交集、并集、差集。
# 应用场景
Set 类型比较适合用来做数据去重和保障数据的唯一性,还可以用来统计多个集合的交集、并集、补集,当我们存储的数据是无序且需要去重的情况下,比较适合使用集合类型来存储。需要注意 set 的集合计算复杂度较高,在数据量大的情况下,直接执行这些计算会导致 Redis 实例阻塞,
- 点赞记录:一个用户只能对一篇文章点赞
- 共同关注 :交集
- 抽奖活动:防止重复中奖
# Zset
zset 相比较与 set 类型多了一个排序属性,score 分值。对于有序集合 zset 每个存储元素相当于是有两个值组成,一个是有序集合的元素值,一个是排序值,
# 内部实现
内部采用了压缩列表或跳表实现的,若有有序集合元素个数小于 128 个。并且每个元素值小于 64 字节。redis 会使用压缩列表,否则则使用跳表。在 redis7.0 中跳表废弃了使用了 listpack 数据结构来实现
# 应用场景
排行榜、电话姓名、有序排列
高级数据类型
# BitMap
位图,是一串连续的二进制数组 [0,1] 可以通过 offset 定位元素,BitMap 通过最小的单位 bit 来进行 0|1 的设置,表示某个元素的值或状态,时间复杂度为 O1,
内部实现:本身利用了 String 作为底层数据结构,String 会保存为二进制的字节数组,redis 就把每个 bit 位利用起来,用来表示一个元素的二进制状态。
应用场景:
签到打卡,判断用户登录状态 连续前端用户数,
# HyperLogLog
是一种用于统计基数的数据集合类型,基数统计是指统计一个集合中不重复元素个数, HyperLoglog 的统计规则是基于概率完成的,不是非常准确,而 HyperLogLog 的优点在于,输入元素的数量或体积很大时,计算基数所需要的内存空间是固定且很小的。
应用场景: 百万级 UV 网页计数
# GEO
这个是用于存储地理位置信息的,并可以对存储的信息进行计算操作,例如搜索附近的餐馆,打车等等。
内部原理:
底层采用了 Sorted Set 集合类型,GEO 类型使用了 GOEhash 编码方法实现了经纬度到 sorted set 中元素权重分数的转换,其中的两个关键机制计算对二维地图做区间划分和对区间进行编码。一组经纬度落在某个区间后,就用区间的编码值来标识。
# Stream
redis5. 新增的消息队列数据类型,用于完美地实现消息队列,它支持消息的持久化、支持自动生成全局唯一 ID、支持 ack 确认消息的模式、支持消费组模式等,让消息队列更加的稳定和可靠
- 消息保序:XADD/XREAD
- 阻塞读取:XREAD block
- 重复消息处理:Stream 在使用 XADD 命令,会自动生成全局唯一 ID;
- 消息可靠性:内部使用 PENDING List 自动保存消息,使用 XPENDING 命令查看消费组已经读取但是未被确认的消息,消费者使用 XACK 确认消息;
- 支持消费组形式消费数据
# 二、Redis 数据结构篇
redis 本身就是一个键值型的数据结构
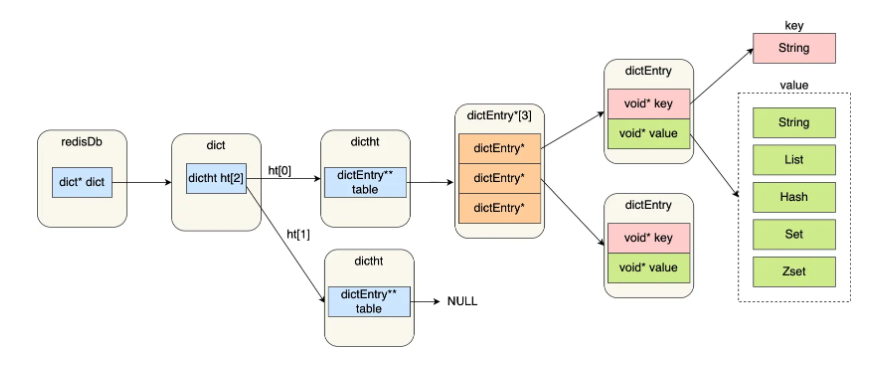
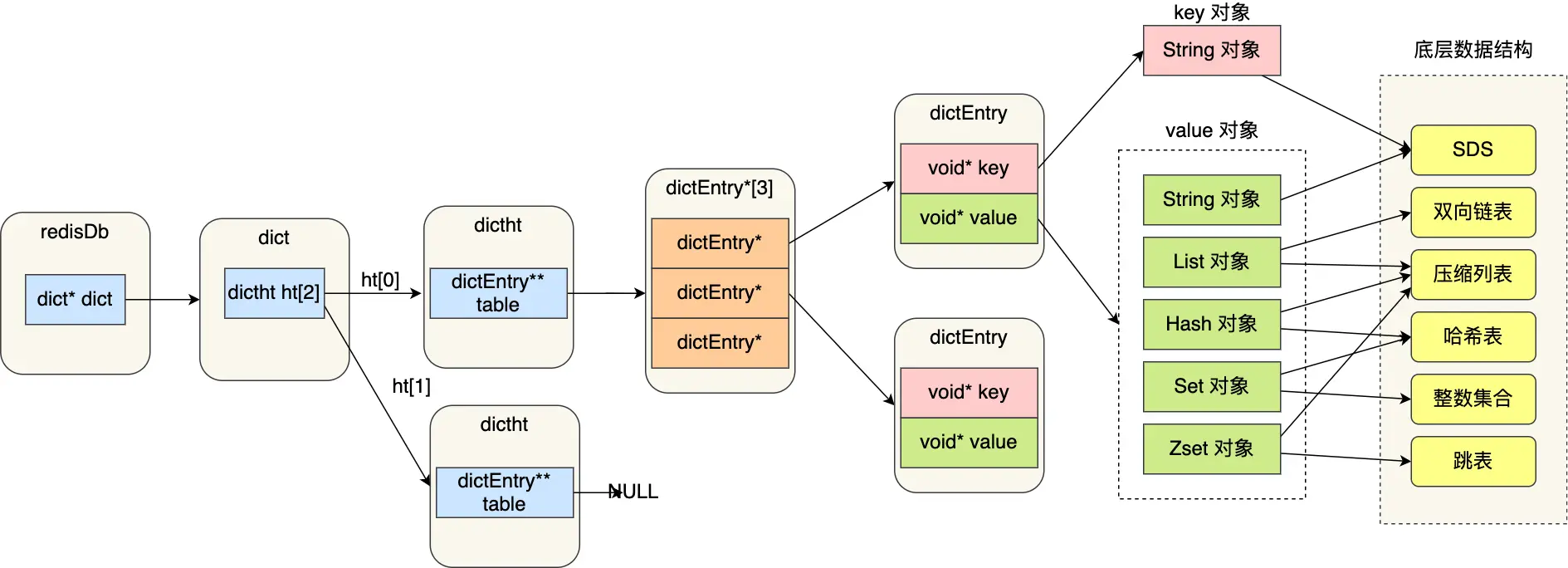
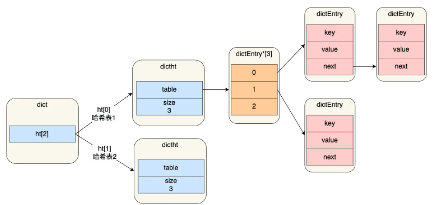
- redisDb 结构,表示 Redis 数据库的结构,结构体里存放了指向 dict 结构的指针。
- dict 结构,结构体里存放了 2 个哈希表,正常情况下都是用哈希表 1,哈希表 2 再 rehash 的时候才会使用
- dictht 结构表示哈希表的结构,结构体存放了哈希表数组,每个数组都指向应该哈希表节点的结构体指针 dictEntry 结构,表示哈希表节点的结构,结构里存放了 **void * key 和 void * value 指针, key 指向的是 String 对象,而 value 则可以指向 String 对象,也可以指向集合类型的对象,比如 List 对象、Hash 对象、Set 对象和 Zset 对象。
![image-20230905225939660]()
# SDS
redis 是使用 C 语言实现的,但是他没有直接使用 C 语言的 char* 字符数组,而是自己封装了一个名为简单动态字符串的数据结构,来表示字符串, 也就是 SDS
不使用 c 语言的默认字符数组是因为:
- C 语言默认的字符数组是以 \0 表示结束的,在二进制数据中经常有 \0 这样的数据串,使用就不能保存
- C 语言的字符串是不会记录自身的缓冲区大小的。容易发生溢出
- 字符串操作函数不高效且不安全,比如有缓冲区溢出的风险,有可能会造成程序运行终止
![image-20230905225948684]()

- SDS 的自动扩容机制 如果所需要的长度小于 1mb 。那么是翻倍扩容,如果超过 1Mb 是按照 newlen=1mb
- flags,用来表示不同类型的 SDS。一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64,这 5 种类型的主要区别就在于,它们数据结构中的 len 和 alloc 成员变量的数据类型不同。
- sdshdr16 类型的 len 和 alloc 的数据类型都是 uint16_t,表示字符数组长度和分配空间大小不能超过 2 的 16 次方。
- sdshdr32 则都是 uint32_t,表示表示字符数组长度和分配空间大小不能超过 2 的 32 次方。
# 链表
redis 的链表结构很简单,就前置节点,后置节点,数据;但是封装了一个 List 数据结构
1 | typedef struct list { |
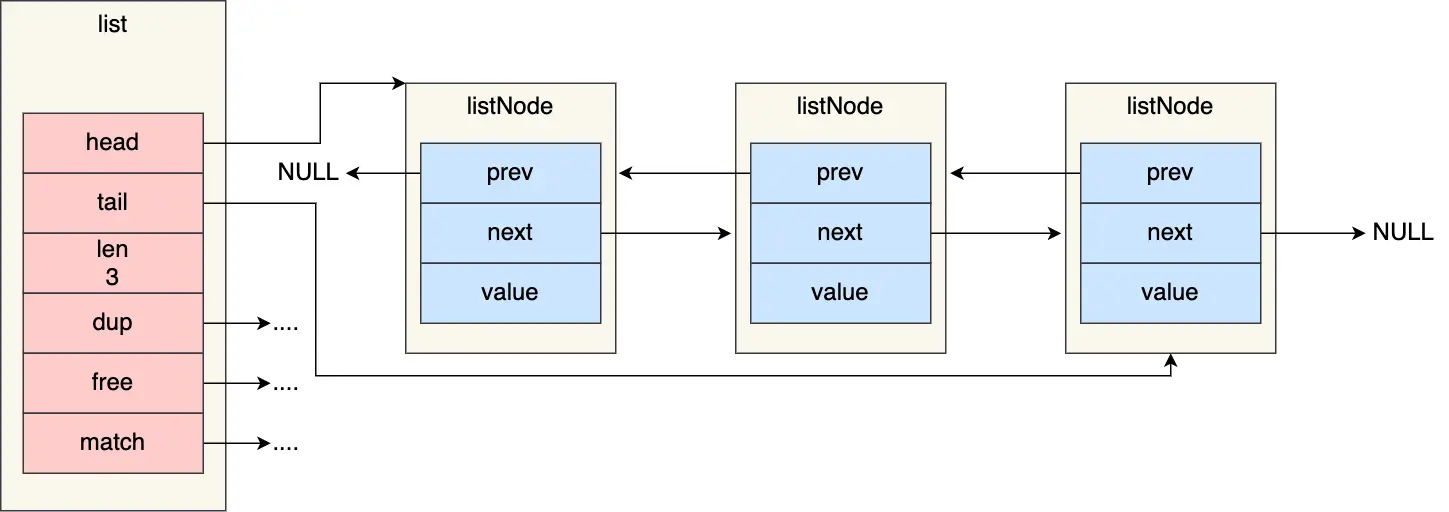
- ListNode 链表节点的结构里设置有 prev 和 next,获取某个节点的前置节点或后置节点的时间复杂度只需要 O (1);
- listl 因为有表头指针和标为指针,所以获取表头和表尾节点的时间复杂度是 O (1)
- list 结构因为提供了链表节点数量 len,所以获取链表中的节点数量的时间复杂度只需 O (1);
# 压缩列表
压缩列表的最大特点就是他被设计成一种内存紧凑型的数据结构,占用的是一块连续的内存空间,不仅可以利用 CPU 缓存,而且可以针对不同的长度的数据进行相应编码,这种方式可以有效的节省内存开销。

- zlbytes 记录整个压缩列表占用内存对内存字节数
- zltail 记录压缩列表尾部节点距离起始地址由多少字节,也就是列尾偏移量,
- zllen:记录压缩列表包含的节点数量
- zlend: 标记压缩列表的结束点 1
- 压缩列表查找表头和表尾元素很快,只需要 O (1) 但是查找其他元素就没那么快了,因此压缩列表不适合保存过多元素
# 哈希表
哈希表是一种保存键值对(key-value)的数据结构。
哈希表中的每一个 key 都是独一无二的,程序可以根据 key 查找到与之关联的 value,或者通过 key 来更新 value,又或者根据 key 来删除整个 key-value 等等。
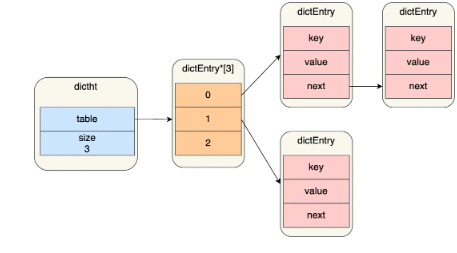
- redis 采用了链式哈希的方式来解决冲突,
- 不过,链式哈希局限性也很明显,随着链表长度的增加,在查询这一位置上的数据的耗时就会增加,毕竟链表的查询的时间复杂度是 O (n)。
随着链表越来越长,hash 的查找速度也就会降低,redis 这里提供了 rehash 也就是上面提到的。
# rehash
其实整个备份就是来做数据迁移了,节点太多 hash 桶太少,需要扩容
- 随着数据逐步增多,触发了 rehash 操作,这个过程分为三步:
- 给「哈希表 2」 分配空间,一般会比「哈希表 1」 大 2 倍;
- 将「哈希表 1 」的数据迁移到「哈希表 2」 中;
- 迁移完成后,「哈希表 1 」的空间会被释放,并把「哈希表 2」 设置为「哈希表 1」,然后在「哈希表 2」 新创建一个空白的哈希表,为下次 rehash 做准备
- 为了避免在 rehash 在数据迁移是,因为拷贝数据导致 redis 性能下降,所以都是采用的渐进式 hash,迁移工作是分多次完成,
触发 rehash 时机:

- 当负载因子大于等于 1 ,并且 Redis 没有在执行 bgsave 命令或者 bgrewiteaof 命令,也就是没有执行 RDB 快照或没有进行 AOF 重写的时候,就会进行 rehash 操作。
- 当负载因子大于等于 5 时,此时说明哈希冲突非常严重了,不管有没有有在执行 RDB 快照或 AOF 重写,都会强制进行 rehash 操作
# 整数集合
整数集合是 Set 对象的底层实现之一,当一个 Set 对象只包含整数值元素,并且元素数量不大时,就用整数集这个数据结构作为底层实现之一,整数集合本质上是一块连续的内存空间吗,整数集合会有一个升级规则,就是当我们将一个新元素加入到整数集合里面,如果新元素的类型(int32_t)比整数集合现有所有元素的类型(int16_t)都要长时,整数集合需要先进行升级,也就是按新元素的类型(int32_t)扩展 contents 数组的空间大小,然后才能将新元素加入到整数集合里,当然升级的过程中,也要维持整数集合的有序性
# 跳表
链表在查找元素的时候,因为需要逐一查找,所以查找效率非常低下,时间复杂度是 O (n) ,跳表是链表的改进版
,多层有序链表,redis 中只有 Zset 用到了跳表,,个人感觉应该是基于链表的二分查找,redis 为什么使用跳表,而不使用红黑树来实现有序集合。
- 有序集合主要是有增、删、改、查四个操作,这些操作红黑树和跳表时间复杂度都是一样的
- 但是基于区间的查询,红黑树的效率就太低了,所以使用跳表
# quickList
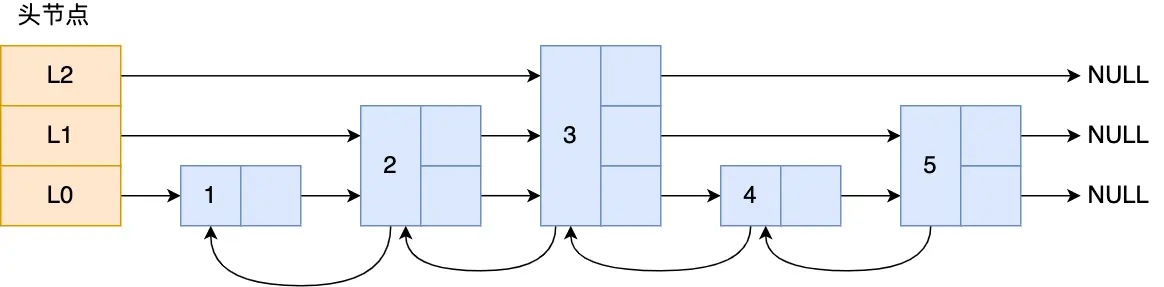
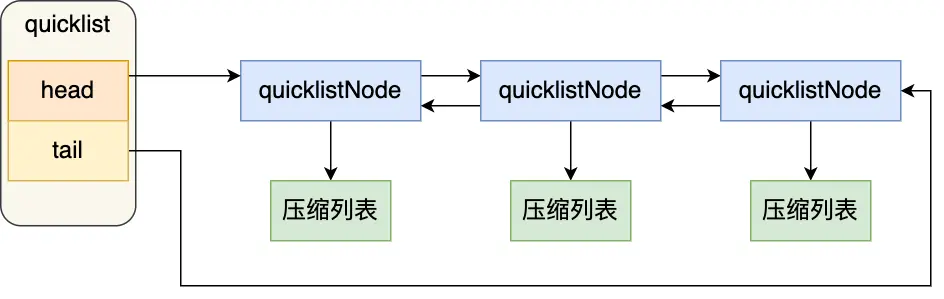
quicklist 其实是双向链表和压缩列表的组合,一个 quicklist 就是一个链表,而链表中每个元素又是一个压缩列表,
压缩列表的不足,如果保存的元素太多,或者元素变大,压缩列表会有连锁更新的情况,quicklist 解决办法,通过控制每个链表节点中的压缩列表的大小或者元素个数,来规避连锁更新的问题。因为压缩列表元素越少或越小,连锁更新带来的影响就越小,从而提供了更好的访问性能。
# listpack
是为了解决压缩列表出现的连锁更新问题,目的是替代压缩列表,它最大特点是 listpack 中每个节点不再包含前一个节点的长度了,压缩列表每个节点正因为需要保存前一个节点的长度字段,就会有连锁更新的隐患

listpack 没有压缩列表中记录前一个节点长度的字段了,listpack 只记录当前节点的长度,当我们向 listpack 加入一个新元素的时候,不会影响其他节点的长度字段的变化,从而避免了压缩列表的连锁更新问题。
# 三、Reids 持久化
# AOF 持久化
redis 每执行一条写操作,就把该命令,以追加的方式写入到一个文件,然后后重启 redis 时,先去读这个这个文件里的命令并执行
配置文件中开启
1 | appendonly yes |
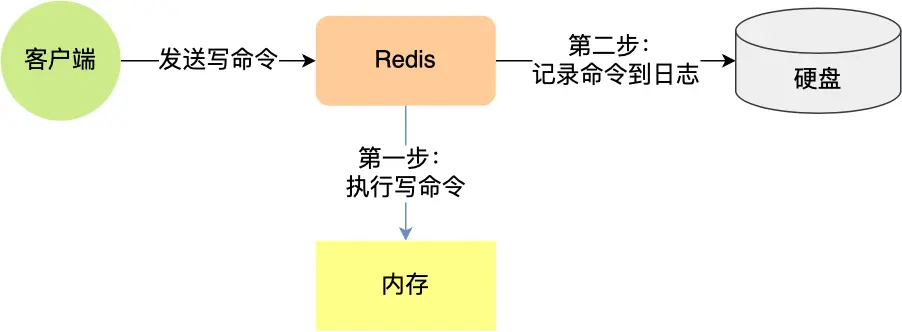
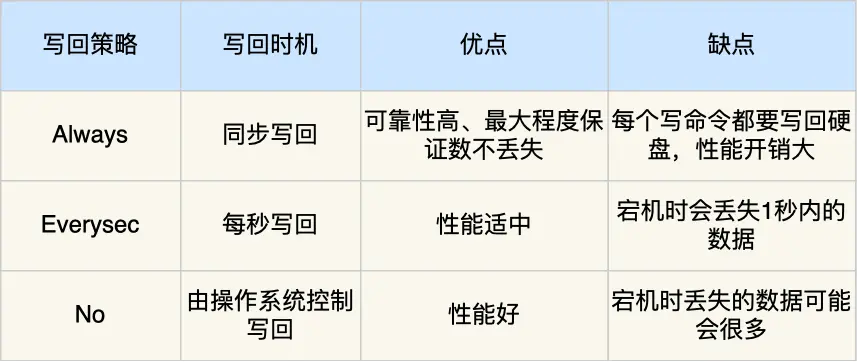
写入数据到数据库和写 aof 日志都是在主进程中完成的,有一定性能损失。当然 redis 也提供了其他的写回机制,可以配置,在 redis .conf 中配置 appendfsync
- Always,这个单词的意思是「总是」,所以它的意思是每次写操作命令执行完后,同步将 AOF 日志数据写回硬盘;
- Everysec,这个单词的意思是「每秒」,所以它的意思是每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,然后每隔一秒将缓冲区里的内容写回到硬盘;
- No,意味着不由 Redis 控制写回硬盘的时机,转交给操作系统控制写回的时机,也就是每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,再由操作系统决定何时将缓冲区内容写回硬盘。
![image-20230905230149806]()
# AOF 重写机制
AOF 日志是一个文件,随着执行的写操作命令越来越多,文件的大小会越来越大。Redis 为了避免 AOF 文件越写越大,提供了 AOF 重写机制,当 AOF 文件的大小超过所设定的阈值后,Redis 就会启用 AOF 重写机制,来压缩 AOF 文件。
redis 的重写机制是在后方子进程 bgrewriteaof 来完成的,
# RDB 持久化
RDB 是内存快照,就是记录一个瞬间的东西,记录的是实时数据,与 AOF 不同,AOF 记录的是命令操作日志,而不是实际的数据。在回复数据时,RDB 要快一些,只需要将 RDB 文件读入内存就可以了,不需要像 AOF 一样还需要执行额外的操作命令。
# 如何生成 RDB
redis 提供了两个命令,分别是 save 和 bgsave,执行了 save 命令会在主线程上生成 rdb 文件,如果写入 rdb 文件太多会阻塞主线程。执行 bgsave 是创建了一个进程来生成 rdb 文件,这样可以避免主线程阻塞。
也可以通过配置文件的选项,每隔一段时间自动执行 bgsave 命令,因为 RDB 快照是全量快照的方式,因此执行的频率不能太频繁,否则会影响 Redis 性能,
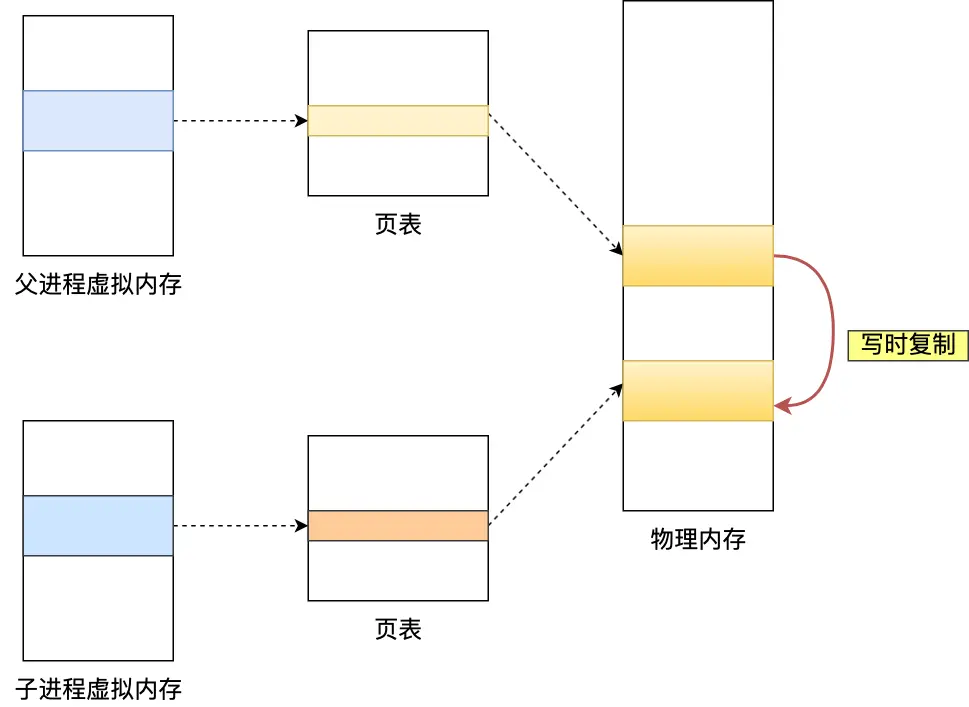
- 执行快照是 redis 的数据是可以继续呗修改的,因为采用了写时复制技术,
执行 bgsave 命令的时候,会通过 fork () 创建子进程,此时子进程和父进程是共享同一片内存数据的,因为创建 子进程的时候,会复制父进程的页表,但是页表指向的物理内存还是一个。共享的内存当另一部分被用户修改时,因为采用了写时复制,所以做复制功能的线程也会被同步。
# 混合持久化
尽管 RDB 比 AOF 的数据恢复速度快,但是快照的频率不好把握:
如果频率太低,两次快照间一旦服务器发生宕机,就可能会比较多的数据丢失;
如果频率太高,频繁写入磁盘和创建子进程会带来额外的性能开销。
这是 redis4.0 提出来的,在配置文件中开启
1 | aof-use-rdb-preamble yes |
当开启了混合持久化时,在 AOF 重写日志时,fork 出来的重写子进程会先将与主线程共享的内存数据以 RDB 方式写入到 AOF 文件,然后主线程处理的操作命令会被记录在重写缓冲区里,重写缓冲区里的增量命令会以 AOF 方式写入到 AOF 文件,写入完成后通知主进程将新的含有 RDB 格式和 AOF 格式的 AOF 文件替换旧的的 AOF 文件。
# 功能篇
# 过期删除策略
# 定时删除
在设置 key 的过期时间时,同时创建一个定时事件,当到达时,由事件处理器执行 key 的删除操作
- 优点:内存可以被尽快地释放。定时删除对内存是最友好的。
- 缺点:定时删除策略对 CPU 不友好,删除过期 key 可能会占用相当一部分 CPU 时间,CPU 紧张的情况下将 CPU 用于删除和当前任务无关的过期键上,会对服务器的响应时间和吞吐量造成影响。
# 惰性删除
不主动删除过期健,每次从数据库访问 key 时检查是否过期,过期则删除,
-
优点:只会使用很少的系统资源,对 CPU 最友好。
-
缺点:如果一个 key 已经过期,而这个 key 又仍然保留在数据库中,那么只要这个过期 key 一直没有被访问,它所占用的内存就不会释放。惰性删除策略对内存不友好。
# 定期删除
每隔段时间随机从数据库中取出一定数量的 key 进行检查,并删除其中过期的 key
- 优点:限制删除操作执行的时长和频率来减少删除操作对 CPU 的影响,同时也能删除一部分过期的数据减少了过期键对空间的无效占用。
- 缺点:内存清理方面没有定时删除效果好,同时没有惰性删除使用的系统资源少。难以确定删除操作执行的时长和频率
# 定期删除 + 惰性删除配合使用
redis 选择的时惰性删除 + 定期删除,配合使用,
Redis 在访问或者修改 key 之前,都会调用 expireIfNeeded 函数对其进行检查,检查 key 是否过期:
- 如果过期,则删除该 key,然后返回 null 客户端;
- 如果没有过期,不做任何处理,然后返回正常的键值对给客户端
从过期字典中随机抽取 20 个 key;检查这 20 个 key 是否过期,并删除已过期的 key;已过期 key 的数量占比随机抽取 key 的数量大于 25%,则继续重复步骤直到比重小于 25%。
# redis 事务
严格来说 redis 事务只是个批处理,有隔离性但是没有原子性
Multi:开启事务
Exec:执行
Discard: 不执行
redis 和 lus 脚本可以进行整合 (用到再学)
# redis 的持久化
redis 是 nosql 数据库,需要把数据保存到磁盘。
redis 所有的数据都是保存在内存中,保存的数据量取决于内存的容量。
redis 提供了两种持久化机制:
-
RDB: 默认开启,快照模式
-
AOF:日志存储,把对 redis 的操作的命令以日志方式存储到文件,当需要恢复数据时,从头到尾把命令执行一遍, 需要手动开启,
-
注:如果同时开启了 RBD 和 AOF 默认是使用 aof 恢复数据。
# RDB(默认使用)
RDB 方式是通过快照( snapshotting )完成的,当符合一定条件时 Redis 会自动将内存中的数据进行,快照并持久化到硬盘
执行时机:
- 符合指定配置的快照规则
- 执行 save 或 bgsave 命令 save 主线程去快照 bgsave 调用异步线程去快照
主线程是单线程 4.0 I/O 操作 已经有多线程概念 - 执行 flushall 或 flushdb
- 执行主从复制操作
可以手动控制快照规则
save 多少秒内 数据变了多少
save “” : 不使用 RDB 存储
save 900 1 : 表示 15 分钟(900 秒钟)内至少 1 个键被更改则进行快照。
save 300 10 : 表示 5 分钟(300 秒)内至少 10 个键被更改则进行快照。
save 60 10000 :表示 1 分钟内至少 10000 个键被更改则进行快照。
快照过程:
- redis 调用系统中的 fork 函数复制一份当前进程的副本(子进程)
- 父进程继续接收客户端的发来的命令,而子进程则开始将内存中的数据写入到硬盘中的临时文件,
- 当子进程写完所有的数据后,会用临时文件替换掉旧的 rdb 文件,至此一次快照完成。
rdb 的优缺点
优点:
RDB 可以最大化 Redis 的性能:父进程在保存 RDB 文件时唯一要做的就是 fork 出一个子进
程,然后这个子进程就会处理接下来的所有保存工作,父进程无需执行任何磁盘 I/O 操作.
缺点:使用 RDB 方式实现持久化,一旦 Redis 异常退出,就会丢失最后一次快照以后更改的所有数据,如果数据集比较大的时候, fork 可以能比较耗时,造成服务器在一段时间内停
止处理客户端的请求;
# AOF
默认情况下 Redis 没有开启 AOF ( append only file )方式的持久化。
开启 AOF 持久化后,每执行一条会更改 Redis 中的数据的命令, Redis 就会将该命令写入硬盘中的 AOF 文件,这一过程会降低 Redis 的性能,但大部分情况下这个影响是能够接受的,另外使用较快的硬盘可以提高 AOF 的性能。
Redis 每次更改数据的时候, aof 机制都会将命令记录到 aof 文件,但是实际上由于操作系统的缓存机制,数据并没有实时写入到硬盘,而是进入硬盘缓存。再通过硬盘缓存机制去刷新到保存到文件。
# 混合持久化方式
这是在 4.0 之后的新版本中新增的。混合持久化是结合了 RDB 和 AOF 的优点,在写入的时候,先把当前的数据以 RDB 的形式写入文件的开头,再将后续的操作命令以 AOF 的格式存入文件,这样既能保证 Redis 重启时的速度,又能减低数据丢失的风险。
有两种开启方式:
1、通过命令行开启;
2、通过配置文件开启
# Redis 集群模式
# 主从复制
# 哨兵集群
# Redis Cluster 集群
# 集群介绍
# 1、搭建主从
主节点:
1 | port 8001 |
# 1、搭建分片集群
测试是在一台服务器上同时启动多个 redis 实例完成的,当然也可以使用多个服务器目前条件有限,
1)先下载安装一台单机的 redis
- 安装 GCC 环境
yum install -y gcc-c++
yum install -y wget - 下载并解压缩 Redis 源码压缩包
wget http://download.redis.io/releases/redis-5.0.4.tar.gz
tar -zxf redis-5.0.4.tar.gz
3. 编译原码
cd redis-5.0.4
make
4. 安装 Redis ,需要通过 PREFIX 指定安装路径,如果不指定默认是安装到 /usr/lcoal/bin 启动的适合不太方便
make install PREFIX=/kkb/server/redis
这步做完最好把安装包里面的 redis.conf 文件复制一份到安装目录下的 bin 目录中,这样启动就方便很多
5. 修改配置文件参数
1 | # 将`daemonize`由`no`改为`yes` |
6. 启动服务
./redis-server redis.conf
7. 关闭服务
./redis-cli shutdown
这样单机就搭建完成了。下面是集群
2)将 bin 目录下的数据持久化文件删掉,在启动集群前要保证是一台全新的 redis. 只保留以下 7 个文件
3) 将 bin 目录复制 6 份,分别命名 1-6,修改每个目录里面的 redi-conf 文件,将端口号分别改为 8801-8806
将配置文件中的 设置为此 cluster-enable yes
另外需要关闭防火墙,或者设置白名单,开启端口等等。不然多个服务器之间集群无法访问
4) 启动所有的 redis,我这里写了一个脚本启动
1 | cd bin-1 |
5)进入 bin-1 中,使用以下命令,创建集群
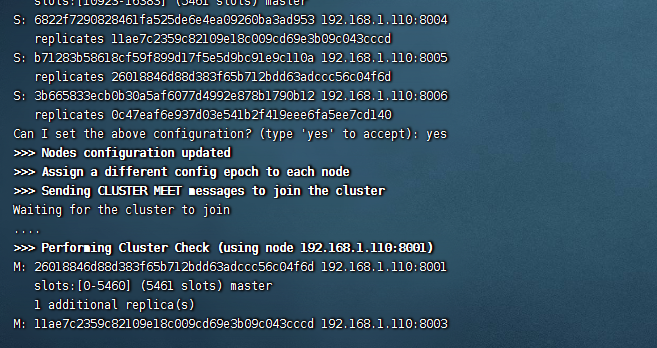
1 | ./redis-cli --cluster create 192.168.1.110:8001 192.168.1.110:8002 192.168.1.110:8003 192.168.1.110:8004 192.168.1.110:8005 192.168.1.110:8006 --cluster-replicas 1 |
最后的参数 1 表示 每个 redis 有一个备份 当主机挂了,备份定上,这也是为什么需要 6 个的原因,
6) 如下图,在过程中输入 yes 启动成功

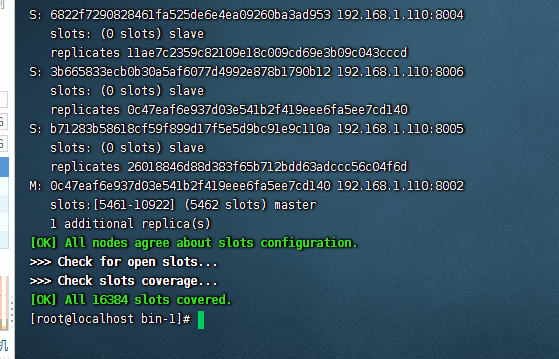
# 2、连接集群
连接集群中任意一台机器都行,例如使用 cli 连接 8001 机器
./redis-cli -h 192.168.1.110 -p 8001 -c
连接集群一定要加 - c 这个参数,不然插入会报错,因为集群模式下,每次新增键都需要进行插槽计算。如果用可视化也是需要集群模式连接
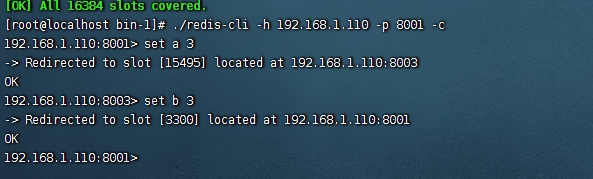
使用 Java 去连接时,需要将所以的节点列出来,然后他会自己去选择连接
# 3、查看集群状态
# 4、集群优缺点
客户端与 Redis 节点直连,不需要中间 Proxy 层,直接连接任意一个 Master 节点
根据公式 HASH_SLOT=CRC16 (key) mod 16384,计算出映射到哪个分片上,然后 Redis 会去相应的节
点进行操作
优点:
(1) 无需 Sentinel 哨兵监控,如果 Master 挂了,Redis Cluster 内部自动将 Slave 切换 Master
(2) 可以进行水平扩容
(3) 支持自动化迁移,当出现某个 Slave 宕机了,那么就只有 Master 了,这时候的高可用性就无法很好的保证
了,万一 Master 也宕机了,咋办呢? 针对这种情况,如果说其他 Master 有多余的 Slave ,集群自动把多余
的 Slave 迁移到没有 Slave 的 Master 中。
缺点:
(1) 批量操作是个坑
(2) 资源隔离性较差,容易出现相互影响的情况。
# redis 数据存储细节
redis 的一个 DB 就是一个 HashTable,
一个 hashtable 由 1 个 dict 结构、2 个 dictht 结构、1 个 dictEntry 指针数组(称为 bucket)和多个 dictEntry 结构组成
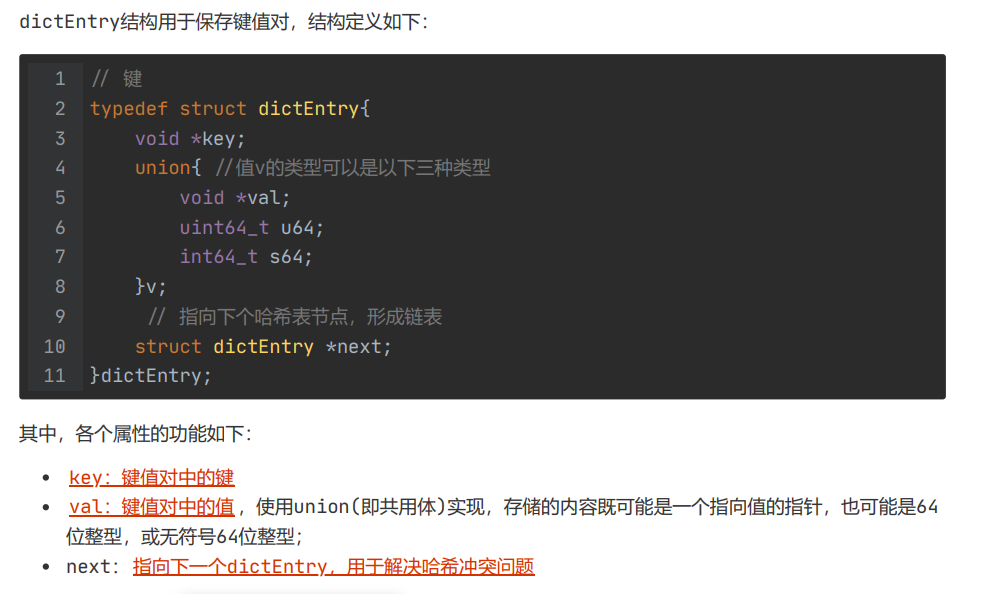
dictEntry 结构用于保存键值对,结构定义如下:
# redis 的对象类型与内存编码
Redis 支持 5 种对象类型,而每种结构都有至少两种编码
-
String
字符串是最基础的类型,因为所有的键都是字符串类型,且字符串之外的其他几种复杂类型的元素也是字符串
字符串长度不能超过 512MB。有三种编码 分别是 int ;embstr ;raw; 数据比较少时使用 embstr 数据比较多时使用 raw
key-value
SDS 结构体进行存储 -
List
列表(list)用来存储多个有序的字符串,每个字符串称为元素;
一个列表可以存储 2^64-1 个元素。
Redis 中的列表支持两端插入和弹出,并可以获得指定位置(或范围)的元素,可以充当数组、队列、栈等。
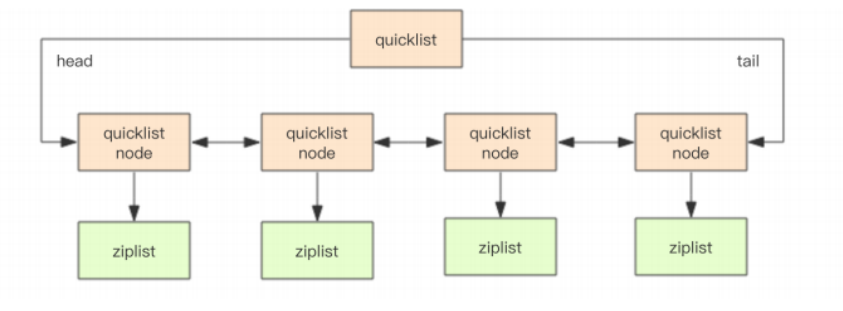
Redis3.0 之前列表的内部编码可以是压缩列表(ziplist)或双端链表(linkedlist)但是在 3.2 版本之后 因为转换也 是个费时且复杂的操作,引入了一种新的数据格式,结合了双向列表 linkedlist 和 ziplist 的特点,称之为 quicklist。有 的节点都用 quicklist 存储,省去了到临界条件是的格式转换。
压缩列表(ziplist)是 Redis 为了节省内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结
构,一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值,放到一个连续内存区。当一个列表只包含少量列表项时,并且每个列表项时小整数值或短字符串,那么 Redis 会使用压缩列表来做该列表的底层实现,
目前使用的是 quicklist 我们仍旧可以将其看作一个双向列表,但是列表的每个节点都是一个 ziplist,其实就是
linkedlist 和 ziplist 的结合。quicklist 中的每个节点 ziplist 都能够存储多个数据元素。
Redis3.2 开始,列表采用 quicklist 进行编码。
![image-20230905230344677]()
-
Hash
- Redis 中内层的哈希既可能使用哈希表,也可能使用压缩列表。
- 只有同时满足下面两个条件时,才会使用压缩列表:
-
哈希中元素数量小于 512 个;
-
哈希中所有键值对的键和值字符串长度都小于 64 字节。
-
Set
但集合与列表有两点不同:集合中的元素是无序的,因此不能通过索引来操作元素;集合中的元素不能有重复。
intSet: 集合中的元素都是数值类型
只有同时满足下面两个条件时,集合才会使用整数集合: -
集合中元素数量小于 512 个;
-
集合中所有元素都是整数值。
如果有一个条件不满足,则使用哈希表;且编码只可能由整数集合转化为哈希表,反方向则不可能。 -
ZSet
有序集合的内部编码可以是压缩列表(ziplist)或跳跃表(skiplist)。
只有同时满足下面两个条件时,才会使用压缩列表:
1)有序集合中元素数量小于 128 个;
2)有序集合中 所有成员长度都不足 64 字节 。
如果有一个条件不满足,则使用跳跃表;且编码只可能由压缩列表转化为跳跃表,反方向则不可能。
# 跳表 zskiplist:
类似于折半查找
# redis 性能优化(简单学了点)
# 优化内存占用
- 利用 jemalloc 内存分配器(默认使用)
- 能用整形 / 长整型的尽量使用,减少使用字符串
- 利用共享对象,引用常量池
- 缩短键值对的存储长度(减少 key 的长度)
# 性能优化
- 设置键值的过期时间
- 使用 lazy free 特性,(惰性删除),不是马上删掉,而是放到删除队列里面,一起删除,或者是开子线程删除。
- 限制 redis 内存大小,设置内存淘汰策略
- 禁用长耗时的查询命令
- 使用 slowlog 优化耗时命令
- 避免大量数据同时失效
- 使用 Pipeline 批量操作数据
- 客户端使用连接池优化
- 使用分布式架构来增加读写速度
- 禁用 THP 特性 /*